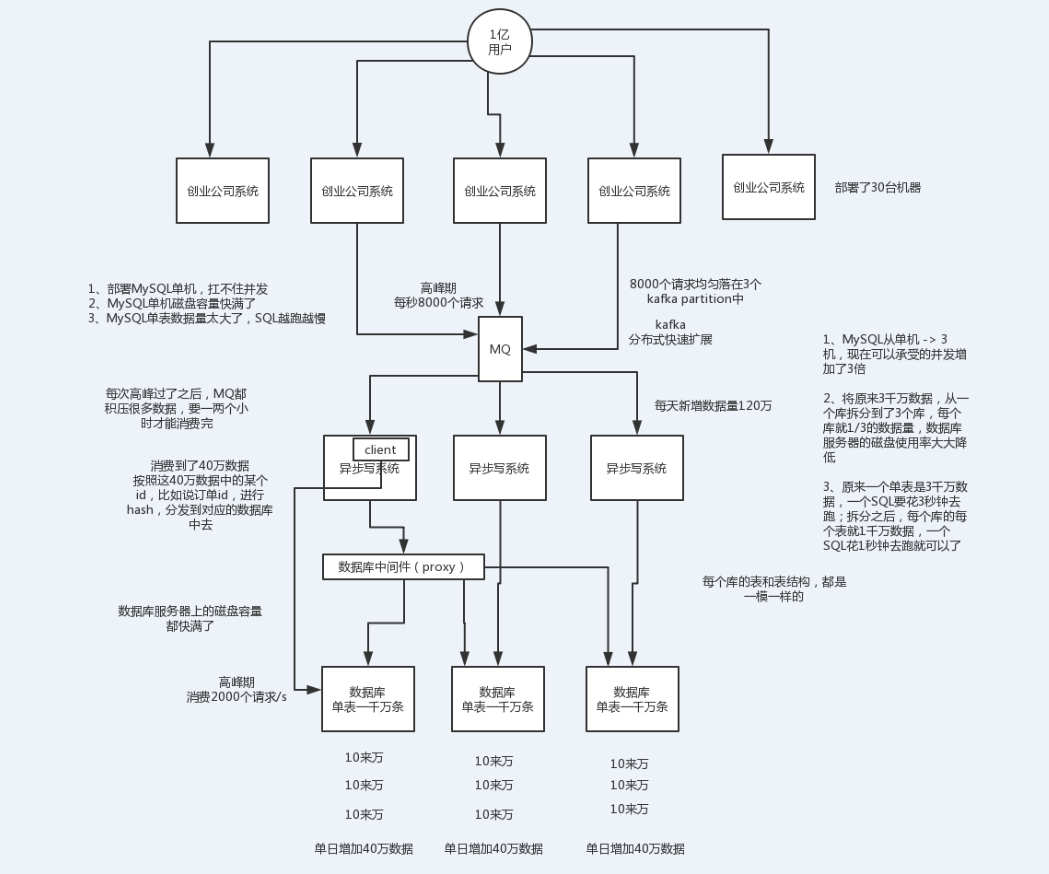
单表到几百万的时候,性能就会相对差一些了,你就得分表了。
分表是啥意思?就是把一个表的数据放到多个表中,然后查询的时候你就查一个表。比如按照用户id来分表,将一个用户的数据就放在一个表中。然后操作的时候你对一个用户就操作那个表就好了。这样可以控制每个表的数据量在可控的范围内,比如每个表就固定在200万以内。
分库是啥意思?就是你一个库一般最多支撑到并发2000,一定要扩容了,而且一个健康的单库并发值你最好保持在每秒1000左右,不要太大。那么你可以将一个库的数据拆分到多个库中,访问的时候就访问一个库好了。
分库分表的中间件:
proxy层的中间件需要独立部署在服务器上
client层的中间件,系统引一个jar包就行,不需要独立部署
cobar:阿里b2b团队开发和开源的,属于proxy层方案。早些年还可以用,但是最近几年都没更新了,基本没啥人用,差不多算是被抛弃的状态吧。而且不支持读写分离、存储过程、跨库join和分页等操作。
TDDL:淘宝团队开发的,属于client层方案。不支持join、多表查询等语法,就是基本的crud语法是ok,但是支持读写分离。目前使用的也不多,因为还依赖淘宝的diamond配置管理系统。
atlas:360开源的,属于proxy层方案,以前是有一些公司在用的,但是确实有一个很大的问题就是社区最新的维护都在5年前了。所以,现在用的公司基本也很少了。
sharding-jdbc:当当开源的,属于client层方案。用的还比较多一些,因为SQL语法支持也比较多,没有太多限制,而且目前推出到了2.0版本,支持分库分表、读写分离、分布式id生成、柔性事务(最大努力送达型事务、TCC事务)。而且确实之前使用的公司会比较多一些(这个在官网有登记使用的公司,可以看到从2017年一直到现在,是不少公司在用的),目前社区也还一直在开发和维护,还算是比较活跃,个人认为算是一个现在也可以选择的方案。
mycat:基于cobar改造的,属于proxy层方案,支持的功能非常完善,而且目前应该是非常火的而且不断流行的数据库中间件,社区很活跃,也有一些公司开始在用了。但是确实相比于sharding jdbc来说,年轻一些,经历的锤炼少一些。
所以综上所述,现在其实建议考量的,就是sharding-jdbc和mycat,这两个都可以去考虑使用。
sharding-jdbc这种client层方案的优点在于不用部署,运维成本低,不需要代理层的二次转发请求,性能很高,但是如果遇到升级啥的需要各个系统都重新升级版本再发布,各个系统都需要耦合sharding-jdbc的依赖;
mycat这种proxy层方案的缺点在于需要部署,自己及运维一套中间件,运维成本高,但是好处在于对于各个项目是透明的,如果遇到升级之类的都是自己中间件那里搞就行了。
垂直拆分:
就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。
每个库表的结构都不一样,每个库表都包含部分字段。
一般来说,会将较少的访问频率很高的字段放到一个表里去,然后将较多的访问频率很低的字段放到另外一个表里去。
因为数据库是有缓存的,你访问频率高的行字段越少,就可以在缓存里缓存更多的行,性能就越好。

水平拆分:
就是把一个表的数据给弄到多个库的多个表里去,但是每个库的表结构都一样,只不过每个库表放的数据是不同的,所有库表的数据加起来就是全部数据。
水平拆分的意义,就是将数据均匀放更多的库里,然后用多个库来抗更高的并发,还有就是用多个库的存储容量来进行扩容。
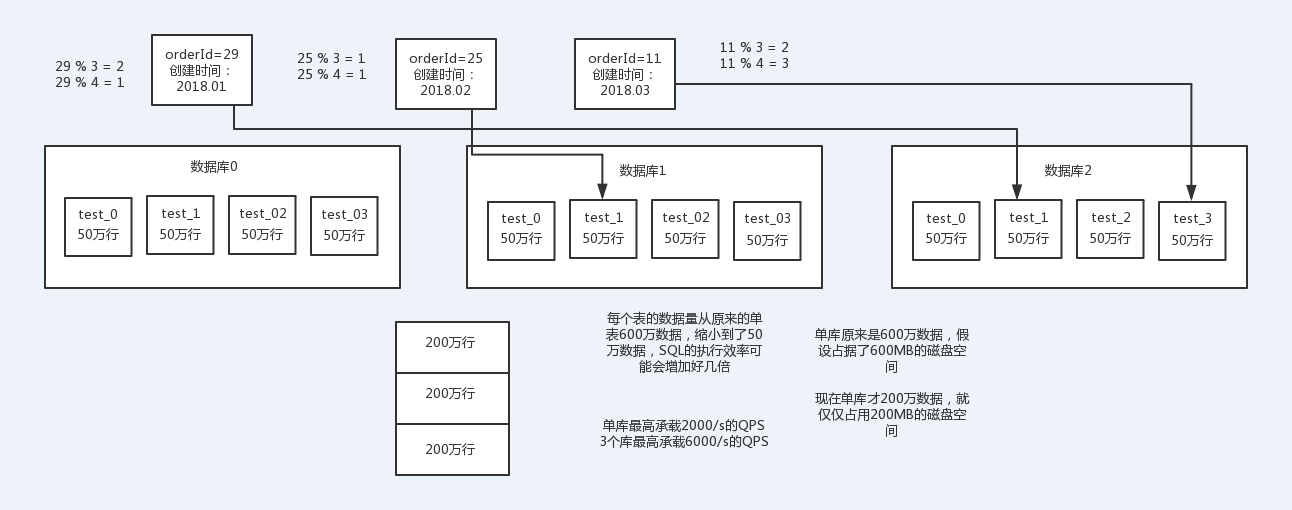
分库分表的方式:
一种是按照range来分,就是每个库一段连续的数据,这个一般是按比如时间范围来的,但是这种一般较少用,因为很容易产生热点问题,大量的流量都打在最新的数据上了;
或者是按照某个字段hash一下均匀分散,这个较为常用。
range来分,好处在于,后面扩容的时候,就很容易,因为你只要预备好,给每个月都准备一个库就可以了,到了一个新的月份的时候,自然而然,就会写新的库了;缺点,但是大部分的请求,都是访问最新的数据。实际生产用range,要看场景,你的用户不是仅仅访问最新的数据,而是均匀的访问现在的数据以及历史的数据
hash分法,好处在于,可以平均分配没给库的数据量和请求压力;坏处在于说扩容起来比较麻烦,会有一个数据迁移的这么一个过程
转自:中华石杉Java工程师面试突击